新浪 Weibo 手机WAP注册验证码破解
March 25 2013
最近研究了一下新浪微博的用户注册,WEB版的注册需要身份证进行实名认证,要想实现注册机的话较为麻烦。于是便另寻捷径,发现其提供了手机注册,只需要邮箱及手机号发送短信激活即可,看上去还算靠普。当然,对于注册所需要填写的验证码肯定是必不可少的,本文将主要记录对该码的破解过程,如下图所示:
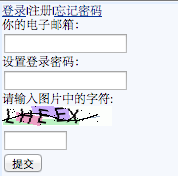
验证码分析
图片特征
不难发现,生成的验证码具体如下特征: 字符随机角度倾斜、随机数字和字母、不规则的背景块、干扰噪点、Y轴为10的所有X轴相素向右移了1相素(放大至相素点可看到)以及一条随机位置的干扰弧线。
User-Agent
随机产生的字符随着 Request Header 中的 User-Agent 的不同所产生的数字和字母范围不同,测试发现使用手机的 UA 生成的字符范围较小,如数字只会随机产生 3 和 4,字母则有10余个,并且只有大写。另外如果同一IP访问获取验证码次数过多则会出来中文验证码(这里破解只针对英文及数字)。
CPT参数
获取验证码时会传入 cpt 作为参数(见如下截图),这意味着每个验证码会对应一个 cpt,且发现同一个 cpt 所生成的验证码字符相同,但其干扰信息会不同。利用该规则可加大后续识别的准确率。

验证码预处理
去除背景色块
首先,在去除之前应当先找到哪些是色块的颜色。通过从图片中可以看出色块颜色相同且区域较大(废话,不然怎么叫色块),并且它们的颜色都以彩色为主,而字的颜色则以黑为主。了解RGB色差值的都知道,一般对于黑色它们的RGB值通常较小,通常128作为彩色的分界值。于是便可以简单判断,当颜色的RGB值都大于128时(不包括白),则认为它是色块的颜色。这里为避免误识别(当出现颜色叠加的情况则无法准确判断),且当它四周的颜色的RGB值同时也大于128时才认为它是色块的颜色。示例代码如下:
// 判断是否为色块的颜色
public boolean isBlockColor(ColorImage cImg, int x, int y){
// 指定X,Y轴相素点及其相临的上下左右是否均为亮色
return cImg.colors[y][x] != WHITE && cImg.colors[y][x] != BLACK
&& isLightColor(cImg.colors[y][x])
&& isLightColor(cImg.colors[y][x-1])
&& isLightColor(cImg.colors[y-1][x])
&& isLightColor(cImg.colors[y+1][x])
&& isLightColor(cImg.colors[y][x+1]);
}
// 判断指定颜色值是否为亮色
private boolean isLightColor(int rgb) {
int r = (rgb >> 16) & 0xff;
int g = (rgb >> 8) & 0xff;
int b = (rgb) & 0xff;
return r >= 128 && g >= 128 && b >= 128;
}既然已经可以判断X,Y的颜色是否为色块色,则可以根据以上方法找到整张验证码图片中的所有色块色并加以去除,代码如下:
// 获取图片中所有为色块的颜色色值
public List<Integer> getBlockColors(ColorImage cImg) {
List<Integer> blockColors = new ArrayList<Integer>();
// find block colors
for (int y = 1; y < cImg.height-1; y++) {
for (int x = 1; x < cImg.width-1; x++) {
if (isBlockColor(cImg, y, x) && !blockColors.contains(cImg.colors[y][x])) {
blockColors.add(cImg.colors[y][x]);
}
}
}
return blockColors;
}通过以上方法获取到所有色块的颜色值之后,只需要再次遍历图片所有相素,当发现X,Y相素值 contains 在色块颜色的 List 中时,则将该X,Y相素值设置为 WHITE 色值即可。以下是去除色块后的前后对比图片效果如下:
去除干扰噪点
噪点的去除相对来说就较为简单了,噪点的特征一般都是独立存在的。只需遍历每个相素点,当某个颜色与其相临的所有颜色均为白色时,则认为它是噪点。代码如下:
private void removeParticles(ColorImage cImg) {
for (int y = 1; y < cImg.height - 1; y++) {
for (int x = 1; x < cImg.width - 1; x++) {
if (cImg.colors[y][x] == WHITE) {
continue;
}
if ((cImg.colors[y][x - 1] == WHITE)
&& (cImg.colors[y - 1][x] == WHITE)
&& (cImg.colors[y + 1][x] == WHITE)
&& (cImg.colors[y - 1][x - 1] == WHITE)
&& (cImg.colors[y + 1][x + 1] == WHITE)
&& (cImg.colors[y - 1][x + 1] == WHITE)
&& (cImg.colors[y + 1][x - 1] == WHITE)
&& (cImg.colors[y][x + 1] == WHITE)) {
cImg.colors[y][x] = WHITE;
}
}
}
}以下是通过上面 removeParticles 方法处理前后的效果对比:
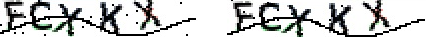
去除干扰弧线
干扰线的去除,个人认为通过递归算法寻找连通线比较不错,不过该方法这里仍然觉得较为复杂,于是这里便通过其它方法实现。首先通过放大相素可以看出(如下图),一个字母的相素组成并非一种颜色(大至都是浅黑包围深黑),而干扰线则是永远都是深黑。

有了以上规则,那么问题就简单了。为了能把处理过程说清楚,下面将通过分解步骤来实现。首先仍然需要遍历整个像素,如果发现深黑(检测值为0xff040204)并且它的四周围都不为白色时,则先将它修改为任意一个颜色(0xFF1234)。代码下如:
for (int y = 1; y < cImg.height - 1; y++) {
for (int x = 1; x < cImg.width - 1; x++) {
//只针对深黑进行处理
if (cImg.colors[y][x] != BLACK) {
continue;
}
if ((cImg.colors[y][x - 1] != WHITE)
&& (cImg.colors[y - 1][x] != WHITE)
&& (cImg.colors[y + 1][x] != WHITE)
&& (cImg.colors[y][x + 1] != WHITE)) {
cImg.colors[y][x] = 0xFF1234;
}
}
}以上处理后对比效果如下所示,那些被包围的深黑已经变成了 0xFF1234 的色值,而干扰线没有变是因为它X轴基本只有1相素且它的四周总会有一方为白色,所以以上变色代码码对干扰线并不会起任何作用:
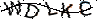
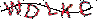
接下来是去线的重点,从上图看出,目前深黑色基本只属于干扰线了(虽然字上仍会残留一些),所以只需要将深黑色去除,并且将0xFF1234(临时色)替换成深黑色即可,代码以处理效果如下:
for (int x = 0; x < cImg.width; x++) {
for (int y = 0; y < cImg.height; y++) {
int color = cImg.getPixel(x, y);
// 删除干扰线
if (color == BLACK) {
cImg.setPixel(x, y, WHITE);
}
// 将临时颜色替换成黑色
if(color == 0xFF1234){
cImg.setPixel(x, y, BLACK);
}
}
} 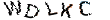
以上是去除干扰线的整个过程的图片变化效果,此方法既高效又简单,且的是字母没有因为去线而导致过多的相素缺失。
字符识别
字符拆分
验证码处理干净之后,便要为识别做准备。由于这里所使用基于字模库的方式来识别字母,所以先必须对每个字母进行拆分,再依个比对识别。这里的拆分方式也较为简单,由于每个字母之间存在较大的缝隙,所以完全可以基于该缝隙作为拆分单元。具体方式是先X轴开始推进,按Y轴从上至下扫描,当发现第一个非白色相素时便认为是字母的X轴坐标,至到扫描遇到白色相素,则认为是该字母的结束(也就得知字母的宽度),依此类推,至到完成5个字母的扫描,最终产生5个矩形坐标,则可按该坐标进行相应的拆分。以下代码是扫描字母的宽度和X坐标:
// 查找单个字母在图片中的位置,返回 Rectangle 对象
// startX: X轴的起始位置,方便查找下一个字r
public Rectangle findLetterRectangle(ColorImage gImg, int startX){
Rectangle rectangle= new Rectangle();
boolean findX = false;
// find x&width: 从左至右扫描
OUTSIDE: for (int x = startX; x < gImg.width; x++) {
for (int y = 0; y < gImg.height; y++) {
// find x
if (!findX && gImg.getPixel(x, y) != -1) { // 0xff = blank
rectangle.x = x;
findX = true;
}
// find width
if(findX){
if(gImg.getPixel(x, y) == -1){
if(y >= gImg.height - 1){
rectangle.width = x - rectangle.x;
break OUTSIDE;
}
}else {
break;
}
}
}
}
// find y&height: 从上至下开始扫描
// 代码略,与上代码类似,可封装成独立方法
}获取到每个字母的 Rectangle 对象之后,即可通过以下代码来进行图片的拆分:
// 将处理好的验证码转成 BufferedImage 对象
BufferedImage bufferedImage = gImg.toBufferedImage();
// 根据矩形进行拆分,获取拆分后的字母图片
BufferedImage subCode = bufferedImage.getSubimage(rectangle.x, rectangle.y, rectangle.width, rectangle.height);
产生字模库
如上图片所示,拆分成单个图片之后,便需针对每个字母建立字模库。该步会有一定的手工量,我这里的做法是为每个字母建立一个目录,该目录下存放针对该字母的字库集,前期先进行手工分类少量的字库,后续再通过相似度算法(参考下节)在进行识别同时自动积累字模库。部分字模库截图如下:
基于字模库的识别
字库的识别这里所采用的字符串相似度算法(Levenshtein Distance),可能你会想到,这这是图片的比较,跟字符串有什么关系?所有这里先须将图片转成字符串,转换过程如下所示:
public String imageToString(ColorImage cimg){
StringBuilder builder = new StringBuilder();
for(int x = 0; x < cimg.width; x++){
for(int y = 0; y < cimg.height; y++){
if(cimg.getPixel(x, y) == WHITE){
builder.append(0);
} else {
builder.append(1);
}
}
}
return builder.toString();
}有了以上转换 imageToString 之后,便可用来相似度比较,通过将拆分后的指定字符与字库进行比较,获取与之相似度最近的字母,代码如下:
// 获取与指定图片字符最相似的字符
public String getMostSimilarLetter(ColorImage image){
final String origin = imageToString(image); // 需要识别的字母
int min = 100;
String letter = null;
// 字模库文件夹
File[] letterDirs = new File("letters/").listFiles();
// 将需要识别的字母与字模库中每个图片进行比较,获取其中相似度最小的字母
for(File letterDir : letterDirs){
File[] letters = letterDir.listFiles();
for(File letterFile: letters){
String source = imageToString(letterFile);
int curDistance = StringUtils.getLevenshteinDistance(source, origin);
if(curDistance <= min){
letter = letterDir.getName();
min = curDistance;
}
}
}
return letter;
}–
至此破解的每个步骤基本上已经完成,接下来将以上每个环节串起来(保证产生一定的字模库)进行一下测试,运行过程如下图所示:

基本上识别率能达到 98% 以上, 且字模大概在 1500 个左右。值得一提的是,之所以能达到这么高的准确率,主要还在于前面所说的 CPT 参数,通过多次访问同一验证码,多次猜测,最终再将统计结果(出现次数最多)并合并(如上图日志所示),则可以达到最佳准确率。
最后再说说效率吧,以上使用了将近15/s的时间,其主要花费在于网络(因多次下载验证码图片),其二是由于每个字母与字模库的比较过程会较为消耗时间,且随着字模库越大则越慢,优化做法可将字模库每个图片的 String 值缓存在内存中,直接从内存中读取并比较会提高一定的效率。